
Извлечено из блога
Художник в тумане — понимая модели диффузии через басню
Выбранные абзацы с AI-размещёнными иллюстрациями. Прочтите полный пост для всей статьи.
Он взял лист белой бумаги — и вместо того чтобы коснуться её кистью, покрыл весь лист хаотичной тёмно-серой краской. Зрители недоумевали: «Ты её портишь». Wu Sheng ответил: «Настоящая картина должна сначала научиться скрываться».

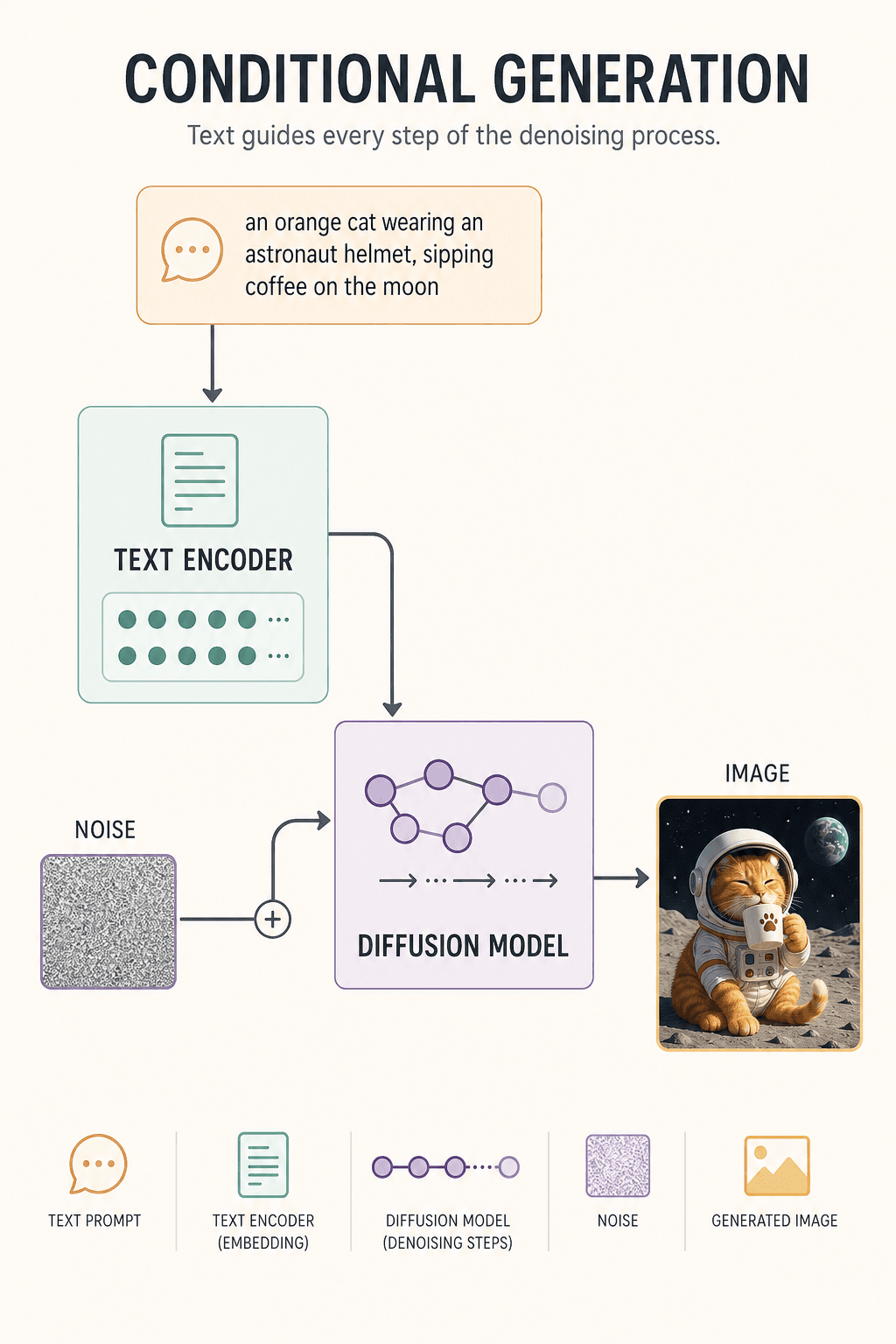
В обучении модель учится так: возьмите реальное фото кошки и многократно добавляйте шум — на шаге 1 ещё чётко, на шаге 100 начинает размываться, на шаге 1000 — чистая случайная ТВ-помеха. Потом обучите AI отвечать на обратное: «Если сейчас выглядит так грязно, как, вероятно, выглядел оригинал?»

Когда генерация идёт по-настоящему, у модели нет картинки — только клякса случайного шума и промпт. Шаг 1: крошечное удаление шума. Шаг 30: появляется силуэт кошки. Шаг 80: появляется шлем. Шаг 150: оформляется лунный фон. Шаг 300: детали оседают. Изображение рождается.

Почему текст может направлять изображение? Из-за Text Encoder. Он превращает «рыжий кот + астронавт + луна + кофе» в вектор чисел и на каждом шаге удаления шума напоминает модели: «Рыжий кот, не чёрный. На луне, не на кухне».
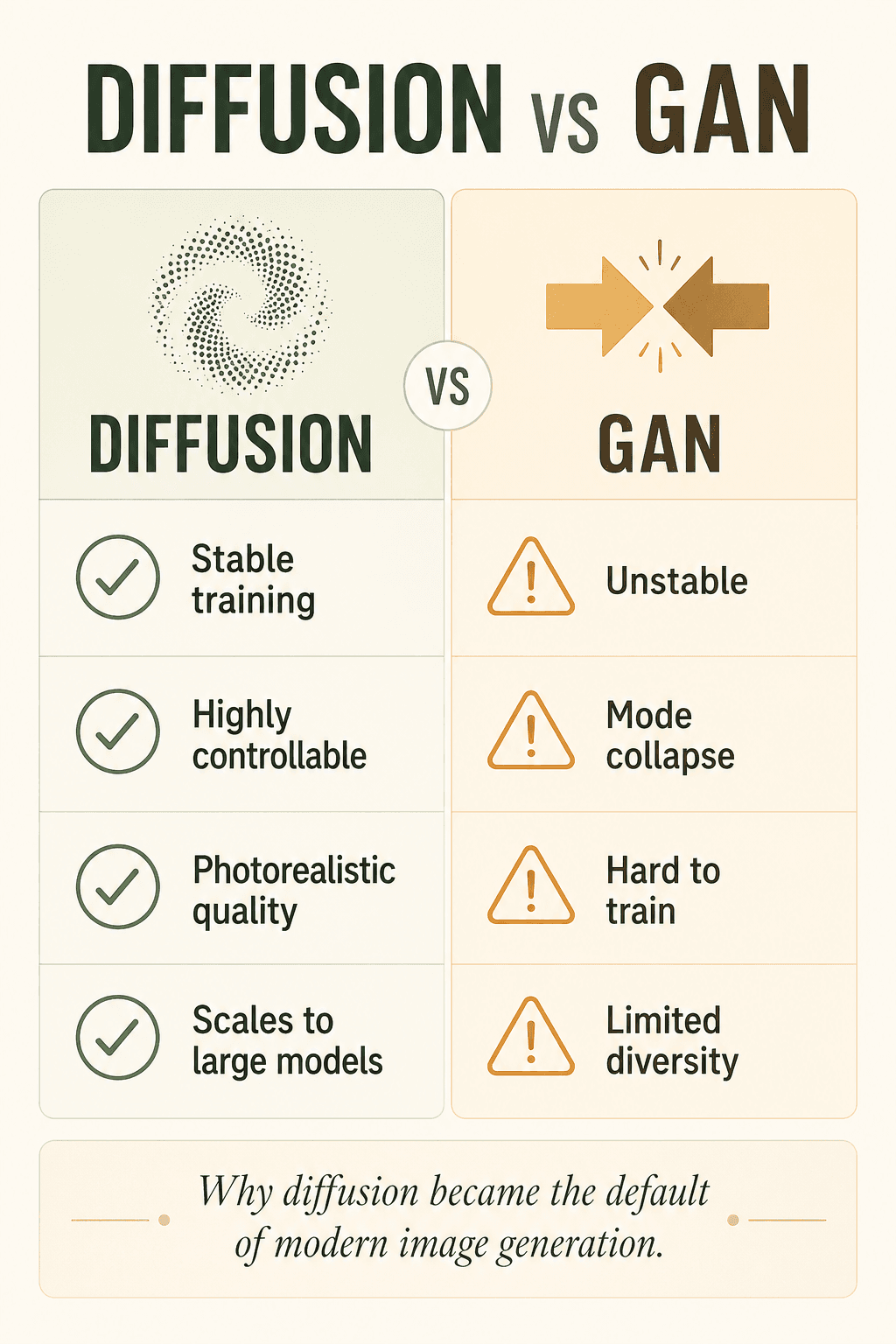
Ранние AI-генераторы изображений полагались на GAN, но GAN были печально нестабильны, склонны к коллапсу мод, тяжелы в обучении и ограничены по разнообразию. Диффузия более стабильна, более контролируема, выше по качеству и лучше масштабируется — поэтому тихо стала дефолтом современной эпохи.
—— ~1500 слов опущено ——