
Estratto dal blog
Il Pittore nella Nebbia — Capire i Modelli di Diffusione Attraverso una Favola
Paragrafi selezionati con le illustrazioni posizionate dall'AI. Leggi il post completo per l'articolo intero.
Prese un foglio di carta bianca — e invece di passarci il pennello, ricoprì l'intero foglio con caotica vernice grigio scuro. Gli astanti erano perplessi: "Lo stai rovinando." Wu Sheng rispose: "Un vero dipinto deve prima imparare a nascondersi."

Durante l'addestramento, il modello impara così: prendi una foto reale di un gatto e aggiungi rumore ripetutamente — al passo 1 è ancora nitida, al passo 100 inizia a sfocarsi, al passo 1000 è puro disturbo televisivo. Poi addestri l'AI a rispondere all'inverso: "Se ora sembra così confusa, come doveva essere l'originale?"

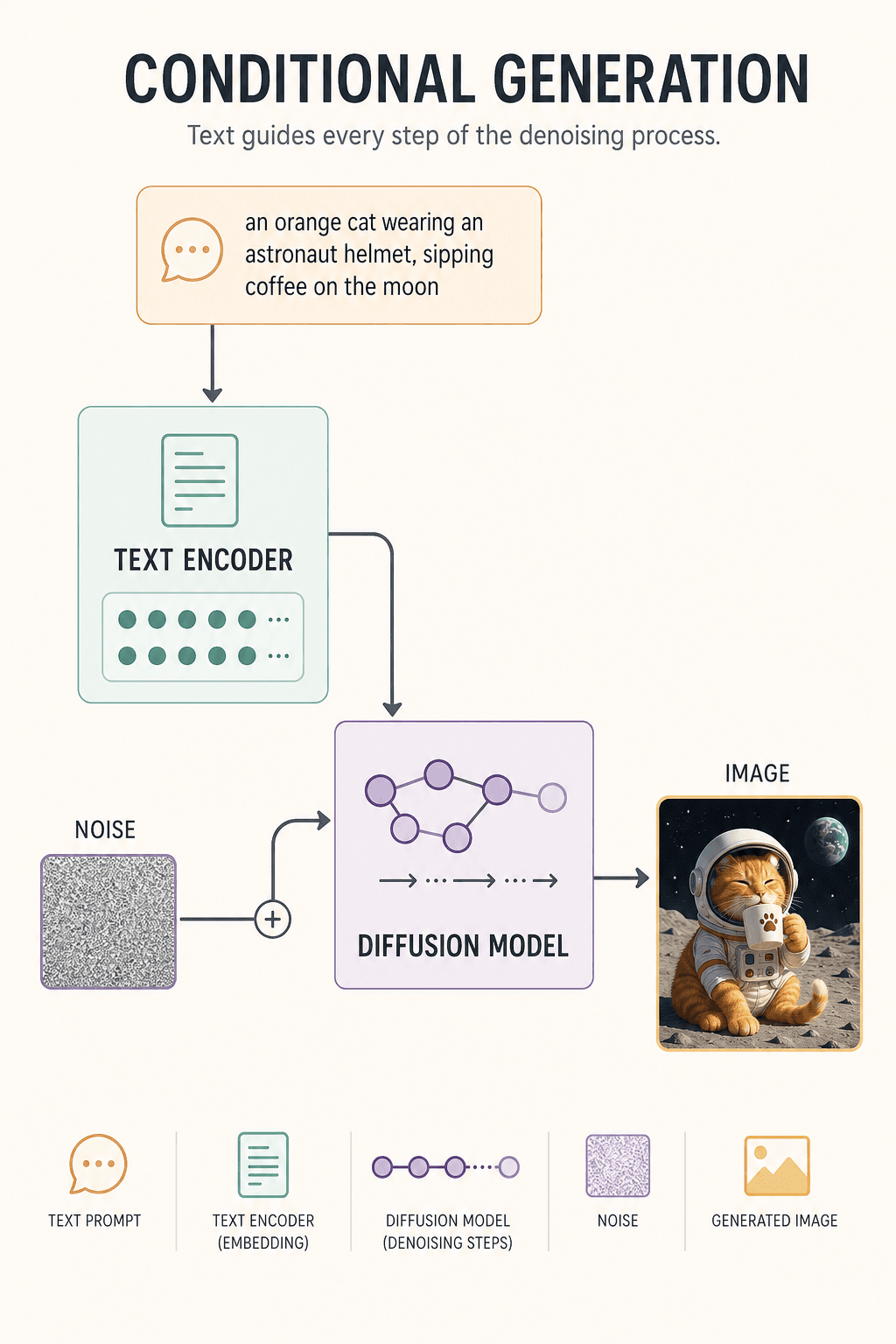
Quando genera davvero, il modello non ha alcuna immagine — solo un blob di rumore casuale e un prompt. Passo 1: piccolo denoising. Passo 30: appare una silhouette di gatto. Passo 80: spunta il casco. Passo 150: si forma lo sfondo lunare. Passo 300: i dettagli si stabilizzano. L'immagine nasce.

Perché il testo può guidare l'immagine? Grazie al Text Encoder. Trasforma "gatto arancione + astronauta + luna + caffè" in un vettore di numeri e durante ogni passo di denoising continua a ricordare al modello: "Gatto arancione, non gatto nero. Sulla luna, non in una cucina."
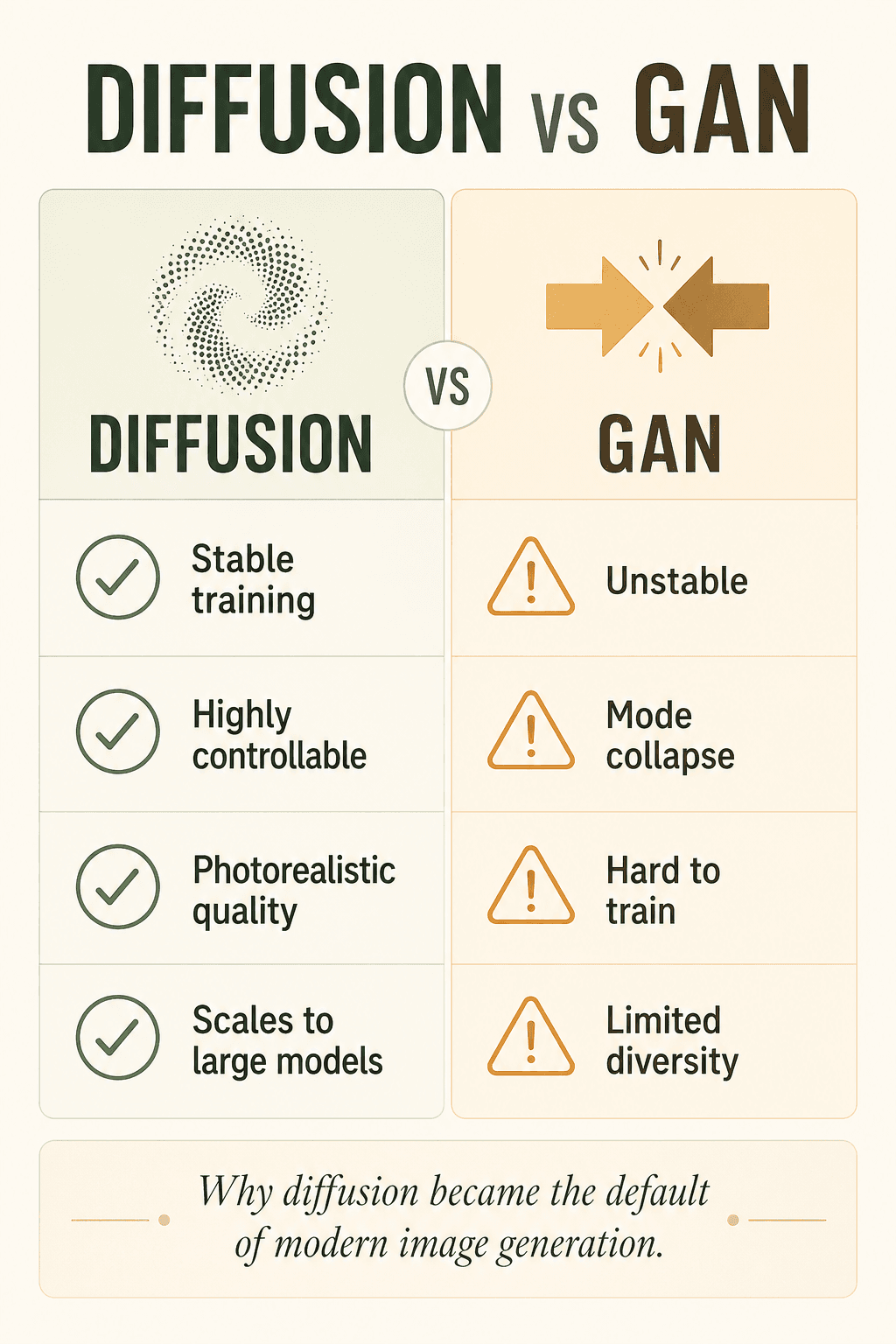
I precedenti generatori AI di immagini si basavano su GAN, ma le GAN erano notoriamente instabili, soggette al collasso dei modi, difficili da addestrare e limitate in diversità. La diffusione è più stabile, più controllabile, di qualità superiore e scala meglio — ed è per questo che è silenziosamente diventata lo standard dell'era moderna.
—— ~1.500 parole omesse qui ——