
블로그에서 발췌
안개 속의 화가 — 우화로 이해하는 디퓨전 모델
AI 배치 일러스트와 함께 발췌된 단락. 전체 아티클은 게시물 전문에서 확인하세요.
그는 흰 종이 한 장을 들고 — 붓을 대는 대신 종이 전체를 어수선한 짙은 회색 페인트로 덮었다. 구경꾼들은 의아해했다: "망치고 있잖아." 우성이 답했다: "진짜 그림은 먼저 숨는 법을 배워야 한다."

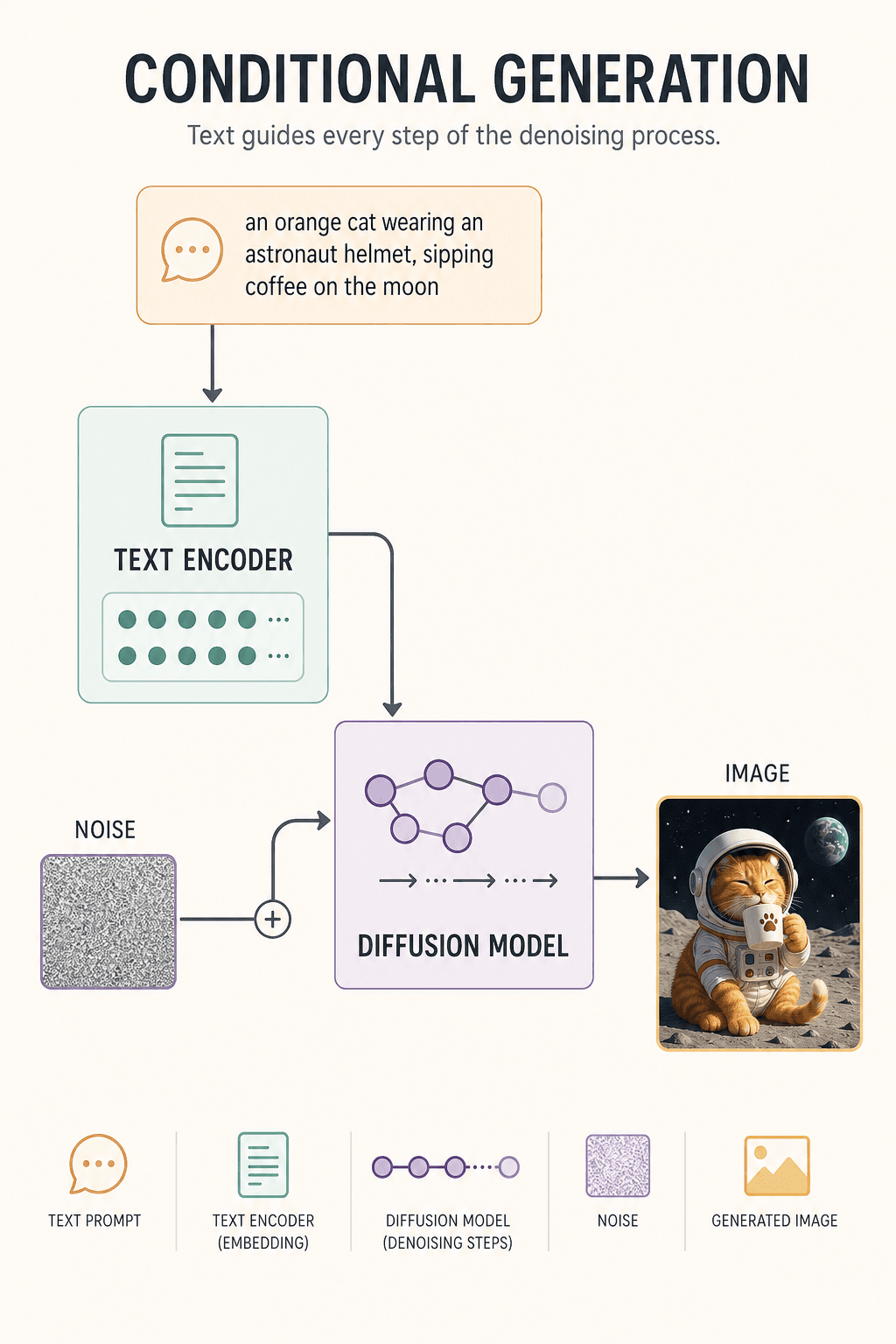
학습 시 모델은 이렇게 배운다: 진짜 고양이 사진을 가져와 노이즈를 반복적으로 추가한다 — 1단계에서는 여전히 또렷하고, 100단계에서 흐려지기 시작하며, 1000단계에서 순수한 무작위 TV 정전기가 된다. 그런 다음 AI에게 반대를 답하도록 학습시킨다: "지금 이렇게 엉망이라면, 원본은 아마 어떻게 생겼을까?"

실제로 생성할 때 모델에는 그림이 없다 — 무작위 노이즈 덩어리와 프롬프트만 있을 뿐. 1단계: 작은 디노이즈. 30단계: 고양이 실루엣이 나타난다. 80단계: 헬멧이 보인다. 150단계: 달 배경이 모양을 갖춘다. 300단계: 디테일이 자리 잡는다. 이미지가 탄생한다.

왜 텍스트가 이미지를 조종할 수 있을까? 텍스트 인코더 덕분이다. 그것이 "오렌지 고양이 + 우주비행사 + 달 + 커피"를 숫자 벡터로 바꾸고, 매 디노이즈 단계마다 모델에게 상기시킨다: "오렌지 고양이, 검은 고양이가 아니다. 달 위에서, 부엌이 아니다."
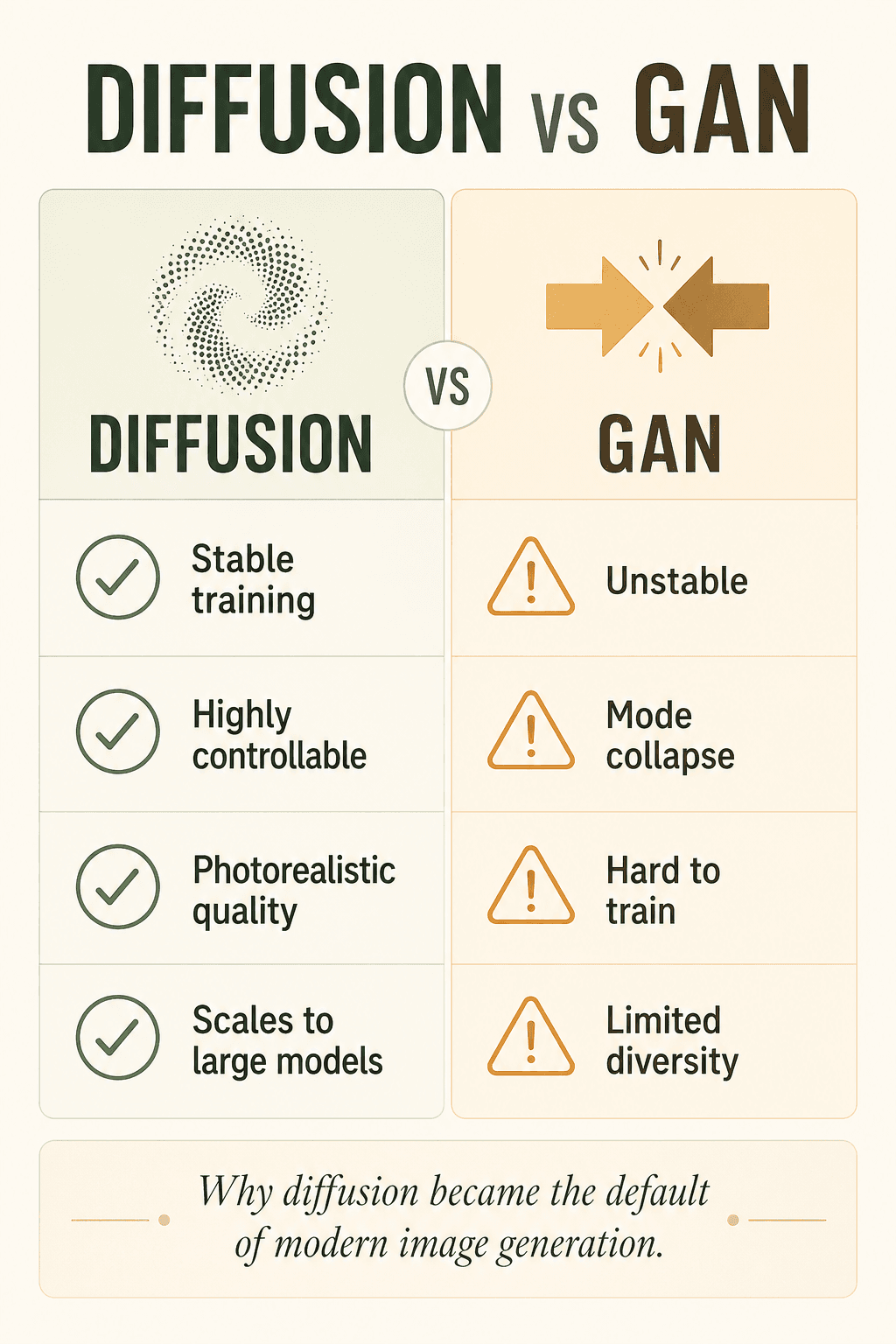
이전의 AI 이미지 생성기는 GAN에 의존했지만, GAN은 악명 높게 불안정했고, 모드 붕괴에 취약했으며, 학습이 어려웠고, 다양성이 제한적이었다. 디퓨전은 더 안정적이고, 더 제어 가능하고, 더 높은 품질을 제공하며, 더 잘 확장된다 — 그래서 조용히 현대의 기본값이 된 것이다.
—— ~1,500자 생략 ——