
오래전, 북쪽 산맥 사이에 일년 내내 짙은 안개로 둘러싸인 작은 도시가 있었다. 백람성이라는 곳이었다. 도시에는 젊은 화가가 살았는데 이름은 무성이었다.
그에게는 이상한 능력이 있었다: 다른 이들은 사물을 또렷이 본 다음 한 획씩 그려 나갔지만 — 그는 정반대였다. 늘 어수선한 안개에서 한 폭의 그림을 천천히 「보아내곤」 했다.
사람들은 이를 황당하다고 여겼다. 「안개 속에 어떻게 그림이 있겠소?」 무성은 그저 미소만 지을 뿐 설명하지 않았다.

떠 있는 도서관
어느 날 노성주가 그를 불러 말했다: 「존재한 적 없는 그림 한 폭을 원하오: 황혼에 바다 위에 떠 있는 도서관, 하늘에 두 개의 달이 떠 있는 모습.」
모두가 박장대소했다. 「세상에 그런 곳이 어디 있어, 어떻게 그리겠소?」
그러나 무성은 고개를 끄덕였다: 「그릴 수 있습니다.」
그는 흰 종이 한 장을 가져왔지만 즉시 붓을 대지 않고, 먼저 종이 전체를 회흑색 물감으로 어수선하게 칠했다. 마치 폭설 후의 창문처럼 아무것도 알아볼 수 없게. 사람들은 더 혼란스러워졌다: 「그건 그림을 망치는 거잖소.」
무성은 답했다: 「진짜 그림은 먼저 숨는 법을 배워야 합니다.」
이후 며칠 동안 그는 매일 한 가지 일만 했다: 어수선함을 조금씩 닦아내는 것. 전부도 아니고, 한 번에도 아닌, 조금씩.
오늘은 빛과 그림자를 닦아내고, 내일은 해안선을, 그 다음 날은 책장의 윤곽이 어슴푸레 나타나고, 또 그 후엔 두 개의 달이 안개 속에 떠올랐다. 그는 마치 짙은 안개와 협상하는 듯했다. 창조가 아니라 끊임없이 묻는 것이었다: 「여기는 원래 무엇이었어야 할까?」 닦아낸 게 틀리면 다시 판단했다. 흐릿하면 계속 관찰했다.
총 49일.
마지막으로 그 종이에는 정말로 바다 위에 떠 있는 도서관이 나타났다. 바다는 고요했고, 책장이 펄럭였으며, 황혼은 황금빛 호흡 같았고, 두 개의 달이 멀리 걸려 있었다.
안개는 어디서 오는가?
도시 전체가 충격에 빠졌다. 누군가 물었다: 「대체 어떻게 한 거요? 처음엔 분명 아무것도 없었는데.」
무성은 고개를 저었다. 「아니오, 처음부터 모든 것이 있었습니다. 다만 모두 안개 속에 섞여 있었을 뿐이지요.」
노성주가 다시 물었다: 「그럼 어디를 닦아내야 할지 어떻게 알았소?」
무성은 답했다: 「먼저 이름을 들었기 때문입니다. '떠 있는 도서관', '두 개의 달', '황혼', '바다'. 이 단어들이 멀리서 들려오는 종소리 같았습니다. 저는 그 소리를 따라 안개 속에서 길을 찾았습니다.」
후에 그는 제자 한 명을 받았다. 제자는 오래 배웠지만 비결을 깨닫지 못했다. 그는 늘 생각했다: 「나는 결과를 직접 그려내고 싶어.」
무성은 그를 산 정상으로 데려갔다. 새벽, 짙은 안개가 산을 덮었다. 그가 말했다: 「저 탑이 보이느냐?」 제자가 답했다: 「보이지 않습니다.」 무성이 물었다: 「그럼 그것이 존재하지 않는 것이냐?」
제자는 침묵했다.
무성이 말했다: 「그림도 마찬가지다. 너는 무에서 유로 세계를 창조하는 것이 아니다. 너는 혼돈 속에서 점진적으로 가장 합리적인 세계로 다가가는 것이다. 진정한 그림은 붓을 대는 것이 아니라 노이즈를 제거하는 것이다.」
여러 해가 지나도 백람성 사람들은 그 화가를 기억했다. 그들은 말했다: 그는 그림을 그린 게 아니다. 세상에게 어수선함에서 어떻게 천천히 질서가 자라나는지를 가르친 것이다.
이야기 뒤의 진짜 지식: Diffusion Model
이 이야기 전체는 사실 현대 AI 이미지 생성의 가장 핵심 원리 — 디퓨전 모델(Diffusion Model) 에 대응한다.
Stable Diffusion, Midjourney, 그리고 우리 사이트가 사용하는 GPT Image 2 — 본질적으로 모두 이 사상을 무겁게 사용한다.
한 문장으로 이해하기:
처음부터 그림을 직접 그리는 것이 아니라, 먼저 무작위 노이즈 덩어리에서 시작해 한 단계씩 「노이즈를 제거」하여 최종적으로 이미지가 된다.
이야기 속 무성처럼: 먼저 종이를 어수선하게 칠하고(순수 노이즈), 한 점씩 닦아내어(점진적 노이즈 제거) 최종적으로 이미지를 얻는다.
학습 단계: AI에게 「노이즈 제거 방법」을 가르치기

학습 시 모델은 이렇게 배운다:
첫째, 진짜 사진 한 장을 가져온다, 예를 들어 고양이 한 마리.
둘째, 끊임없이 노이즈를 추가한다:
- 1회: 고양이가 아직 또렷
- 100회: 흐려지기 시작
- 500회: 거의 보이지 않음
- 1000회: 완전히 무작위 눈송이 점
셋째, AI에게 답하도록 학습시킨다: 「지금 이렇게 어수선하다면 원본 그림은 대략 어떤 모습이었을까?」
즉 「역과정」을 학습한다: 어수선함 → 또렷함.
이게 핵심이다.
생성 단계: 실제로 그림을 그리기 시작

실제 생성 시 AI는 그림이 전혀 없다. 그저 무작위 노이즈 덩어리와 프롬프트 한 줄만 있다:
우주 비행사 헬멧을 쓴 오렌지 고양이가 달에서 커피를 마시는 모습
그러면 모델이 시작한다:
- 1단계: 살짝 노이즈 제거
- 30단계: 고양이의 윤곽이 나타나기 시작
- 80단계: 우주 비행사 헬멧 등장
- 150단계: 달 배경 형성
- 300단계: 디테일 완성
마침내 이미지가 탄생한다.
그렇다면 왜 텍스트가 이미지를 제어할 수 있나?
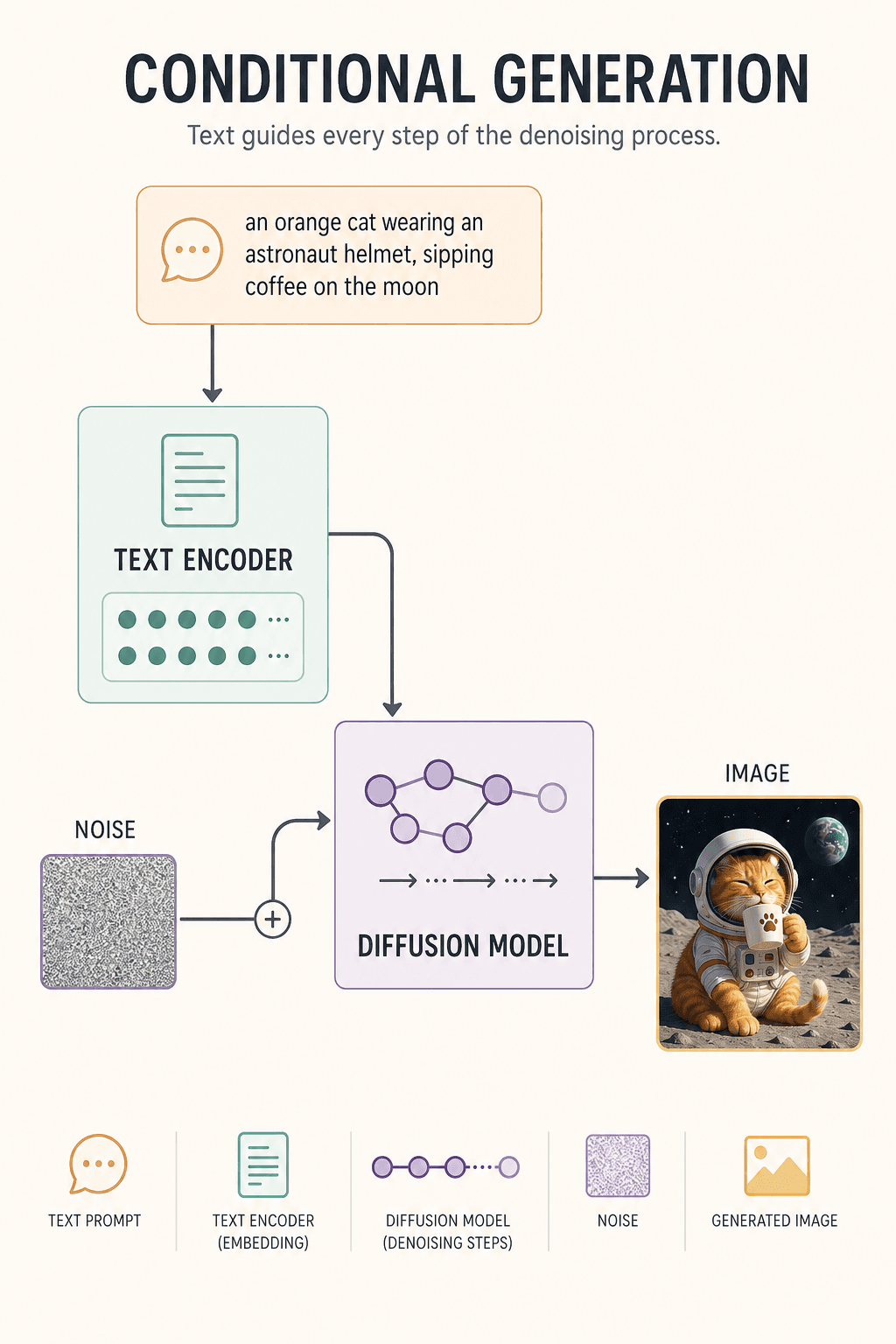
또 하나의 중요한 모듈이 있기 때문이다: Text Encoder(텍스트 인코더).
그것이 「오렌지 고양이 + 우주 비행사 + 달 + 커피」를 수학 벡터(조건 신호)로 변환한 다음, 노이즈 제거 과정 내내 모델에게 끊임없이 상기시킨다:
- 「잊지 마, 오렌지 고양이야, 검은 고양이가 아니라」
- 「달에 있어, 부엌에 있는 게 아니라」
이를 Conditional Generation(조건부 생성) 이라 부른다.
왜 Diffusion이 GAN보다 강한가?
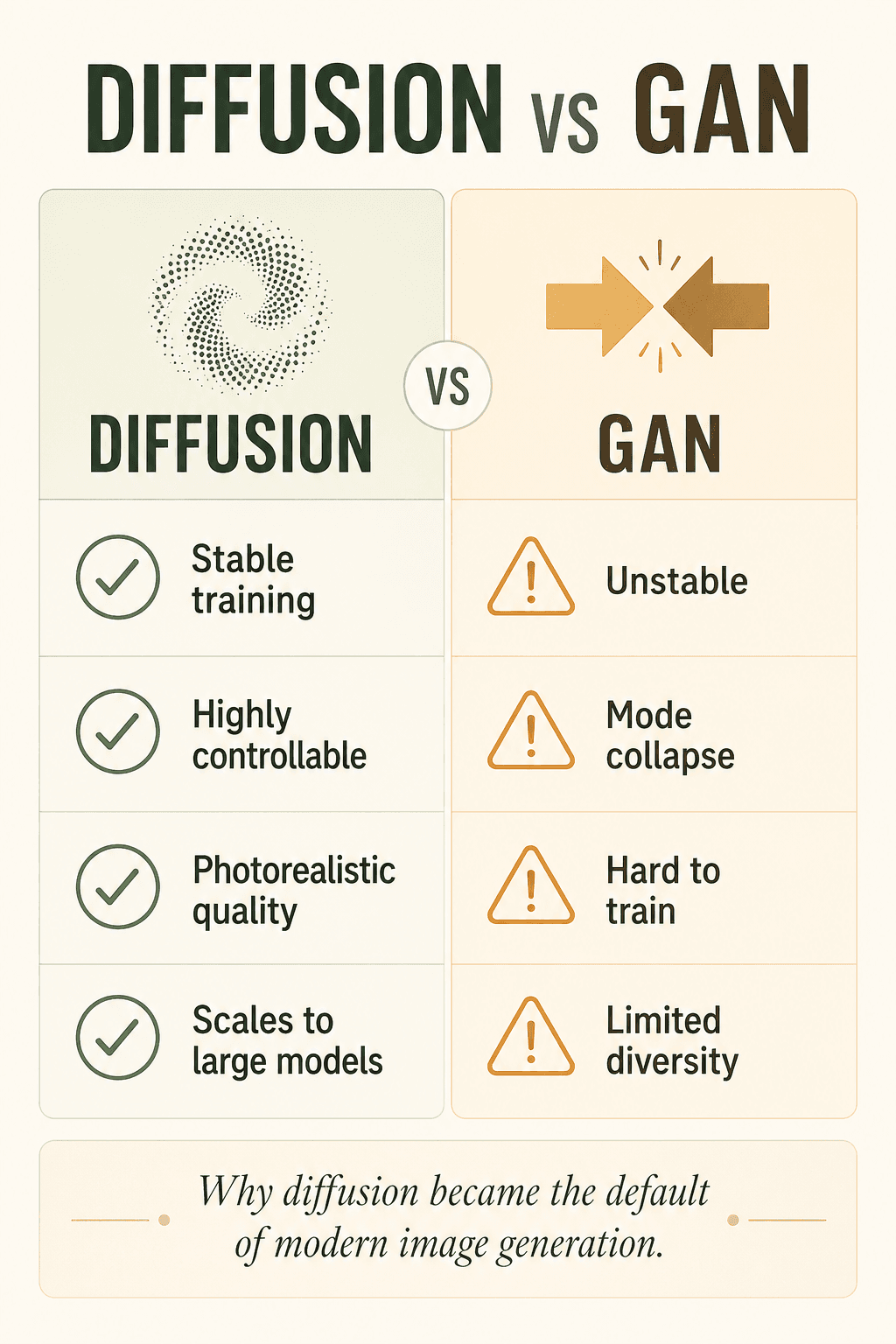
초기의 많은 AI 이미지 생성은 GAN(생성적 적대 신경망)에 의존했다. 그러나 GAN은 종종 불안정하고, 무너지기 쉽고, 학습이 어렵고, 다양성이 부족했다.
반면 Diffusion은 더 안정적이고, 제어가 더 쉽고, 품질이 더 높으며, 대규모 모델 시대에 더 적합하다. 그래서 현재 사실상 주류가 되었다.
가장 본질적인 한 마디
AI 이미지 생성의 본질은 「창조」가 아니라:
확률 공간에서 「가장 이미지처럼 보이는」 결과를 찾는 것이다.
마치 무한한 어수선함 속에서 끊임없이 묻는 것 같다: 「여기서 가장 합리적인 다음 단계는 무엇이어야 하는가?」
이것이 바로 현대 생성형 AI의 가장 깊은 사상이다.