
Extrait du blog
Le peintre dans la brume — comprendre les modèles de diffusion par la fable
Paragraphes extraits avec leurs illustrations placées par l'IA. L'article complet est dans le post original.
Il prit une feuille blanche — au lieu de poser un trait, il la couvrit entièrement d'une peinture grise sombre et dispersée. Le public s'agita : « C'est foutu. » Wu Xing répondit : « Une vraie peinture doit d'abord apprendre à se cacher. »

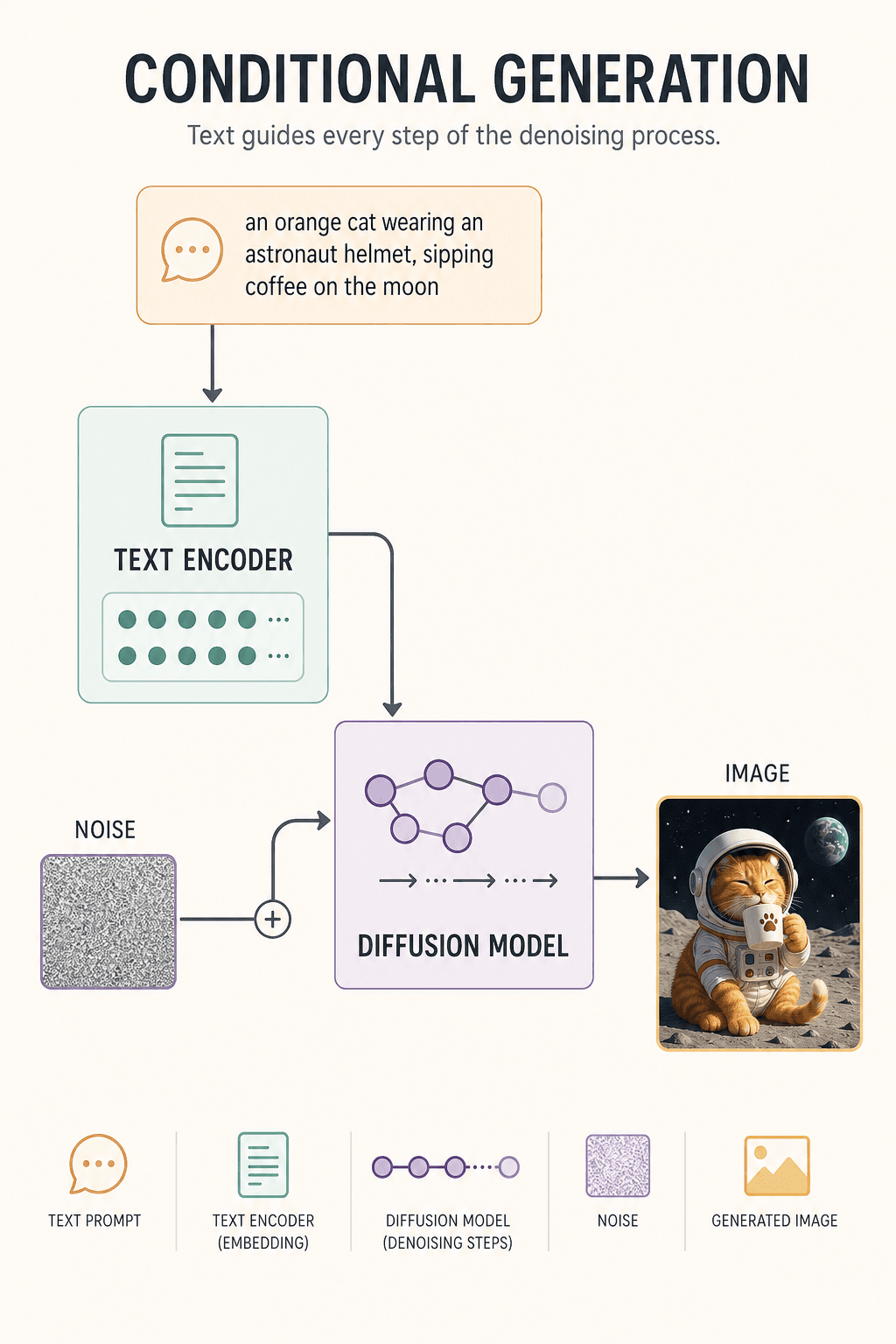
Pendant l'apprentissage, voici comment le modèle apprend : on prend une vraie photo de chat et on lui ajoute du bruit, encore et encore — à 1 étape, c'est encore net ; à 100, ça devient flou ; à 1 000, c'est de la pure neige télé aléatoire. Puis on demande à l'IA de répondre à l'inverse : « Si c'est aussi désordonné maintenant, à quoi ça ressemblait au départ ? »

Au moment de la génération réelle, le modèle n'a pas d'image — juste un bloc de bruit aléatoire et un prompt. Étape 1 : un débruitage léger. Étape 30 : la silhouette d'un chat émerge. Étape 80 : on voit un casque. Étape 150 : la lune en arrière-plan se forme. Étape 300 : les détails se figent. L'image est née.

Pourquoi le texte peut-il piloter l'image ? Grâce à l'encodeur de texte. Il convertit « chat roux + astronaute + lune + café » en un vecteur numérique et, à chaque étape de débruitage, rappelle au modèle : « chat roux, pas noir. Sur la lune, pas dans la cuisine. »
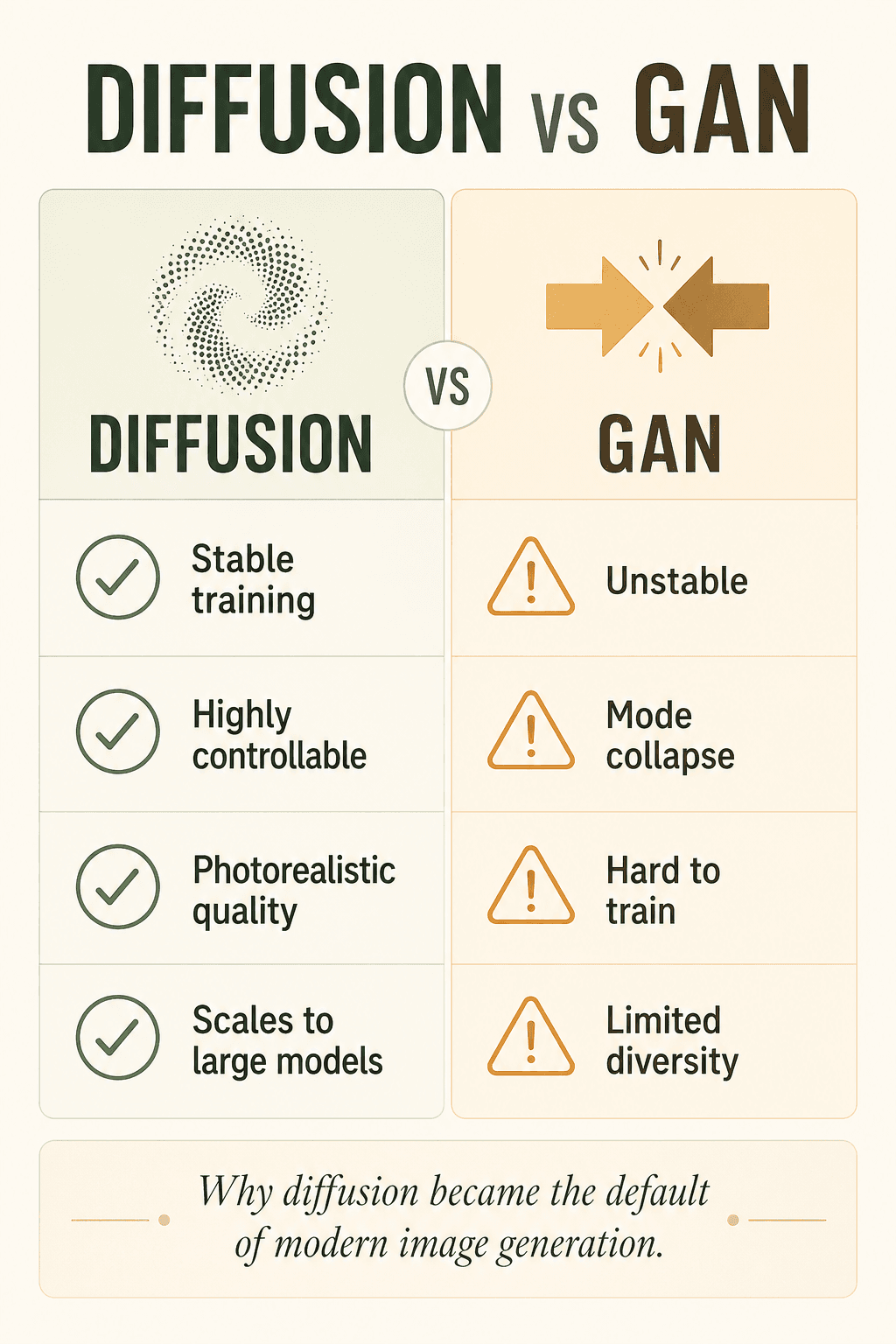
Avant, les générateurs d'images IA s'appuyaient sur les GAN, mais les GAN sont notoirement instables, sujets au mode collapse, difficiles à entraîner et peu diversifiés. Les modèles de diffusion sont plus stables, plus contrôlables, de meilleure qualité et passent mieux à l'échelle — c'est pour ça qu'ils sont silencieusement devenus le standard moderne.
—— environ 1 500 caractères omis ——