
Vor langer Zeit, hoch zwischen den Bergen des Nordens gelegen, war eine kleine Stadt das ganze Jahr über in dichten Nebel gehüllt. Sie hieß Weißnebel. Dort lebte ein junger Maler namens Wu Xing.
Er hatte eine seltsame Gabe: Während andere Maler die Dinge klar sehen und sie Strich für Strich malen, machte er es umgekehrt — er begann immer damit, langsam ein Bild im Herzen eines wirren Nebels „erahnen" zu lassen.
Die Bewohner fanden das lächerlich. „Wie kann es im Nebel ein Bild geben?" Wu Xing lächelte nur, ohne sich zu erklären.

Die schwebende Bibliothek
Eines Tages ließ ihn der Stadtherr rufen: „Ich will ein Bild, das es noch nie gegeben hat — eine Bibliothek, die in der Dämmerung auf dem Meer treibt, unter zwei Monden am Himmel."
Alle brachen in Gelächter aus. „Einen solchen Ort gibt es nicht, wie willst du ihn malen?"
Wu Xing nickte dennoch: „Ich kann es."
Er nahm ein leeres Blatt, malte aber nicht. Er begann damit, das ganze Blatt grau-schwarz zu beschmieren, irgendwie, wie ein Fenster nach einem heftigen Schneesturm: Man konnte nichts mehr erkennen. Alle waren noch verlorener: „Er ruiniert sein Bild nur."
Wu Xing antwortete: „Ein wahres Bild muss zuerst lernen, sich zu verstecken."
In den folgenden Tagen tat er jeden Tag nur eines: ein wenig Unordnung wegwischen. Nicht alles, nicht auf einmal. Nur ein wenig.
Heute wischte er Licht und Schatten weg; morgen die Küstenlinie; übermorgen erschien schwach die Kontur der Regale; später tauchten zwei Monde aus dem Nebel auf. Er schien mit dem Nebel zu verhandeln. Er erschuf nicht — er fragte, immer wieder: „Was sollte hier ursprünglich gewesen sein?" War seine Geste falsch, korrigierte er. War es unscharf, schaute er weiter.
Neunundvierzig Tage insgesamt.
Und schließlich trieb auf diesem Blatt wirklich eine Bibliothek auf dem Meer. Das Meer war ruhig, die Regale zitterten, die Dämmerung atmete wie Gold, und zwei Monde hingen in der Ferne.
Woher kommt der Nebel?
Die ganze Stadt war erschüttert. Jemand fragte: „Aber wie hast du das gemacht? Am Anfang war doch nichts da."
Wu Xing schüttelte den Kopf. „Nein, alles war von Anfang an da. Es war nur im Nebel verborgen."
Der Stadtherr hakte nach: „Aber woher wusstest du, wo du wischen musstest?"
Wu Xing antwortete: „Weil man mir zuerst die Namen gegeben hatte. ‚Schwebende Bibliothek', ‚zwei Monde', ‚Dämmerung', ‚Meer'. Diese Worte waren wie ferne Glocken. Ich folgte ihnen, um meinen Weg im Nebel zu finden."
Später nahm er einen Schüler an. Der Schüler studierte lange, ohne das Wesen zu erfassen. Er dachte immer: „Ich will direkt das Ergebnis malen."
Wu Xing führte ihn auf den Berggipfel. In der Morgendämmerung bedeckte ein dichter Nebel den Gipfel. Er sagte: „Siehst du diesen Turm?" Der Schüler antwortete: „Nein." Wu Xing fragte: „Existiert er deswegen nicht?"
Der Schüler blieb still.
Wu Xing fuhr fort: „Mit dem Malen ist es genauso. Du bist nicht der Schöpfer einer Welt aus dem Nichts. Du näherst dich nach und nach, vom Chaos aus, der kohärentesten Welt. Wirklich malen heißt nicht, den Pinsel anzusetzen — es heißt, das Rauschen zu entfernen."
Jahrelang erinnerten sich die Bewohner von Weißnebel an den Maler. Sie erzählten: Er hat kein Bild gemalt, er hat der Welt gezeigt, wie Ordnung langsam aus dem Chaos hervortreten kann.
Hinter der Fabel das wahre Wissen: Diffusionsmodelle
Diese ganze Fabel beschreibt das zentralste Prinzip der modernen KI-Bildgenerierung: Diffusionsmodelle (Diffusion Models).
Stable Diffusion, Midjourney und das auf unserer Seite verwendete GPT Image 2 — im Kern beruhen sie alle weitgehend auf dieser Idee.
In einem Satz:
Man malt nicht direkt von Anfang an das Bild; man geht von einem Haufen zufälligen Rauschens aus und „entrauscht" Schritt für Schritt, bis ein Bild entsteht.
Wie Wu Xing in der Fabel: Man beschmiert zuerst das Papier (reines Rauschen), wischt Punkt für Punkt (schrittweises Entrauschen) und erhält schließlich ein Bild.
Trainingsphase: Der KI beibringen, wie man „entrauscht"

Beim Training lernt das Modell so:
Zuerst nimmt man ein echtes Foto. Sagen wir das einer Katze.
Dann fügt man unaufhörlich Rauschen hinzu:
-
- Iteration: Die Katze ist noch scharf
-
- Iteration: Sie wird unscharf
-
- Iteration: Man kann sie kaum noch erkennen
-
- Iteration: Reines Fernsehrauschen
Schließlich trainiert man die KI darauf, zu antworten: „Wenn es jetzt so verrauscht ist, wie sollte das Originalbild ausgesehen haben?"
Mit anderen Worten, sie lernt den umgekehrten Weg: Chaos → Schärfe.
Das ist der Kern des Prinzips.
Generierungsphase: ans Malen gehen

Bei einer echten Generierung hat die KI am Anfang kein Bild. Nur einen Haufen zufälligen Rauschens und einen Prompt:
Eine orangefarbene Katze mit Astronautenhelm, die auf dem Mond einen Kaffee trinkt
Und das Modell legt los:
- Schritt 1: leichtes Entrauschen
- Schritt 30: die Silhouette der Katze taucht auf
- Schritt 80: der Astronautenhelm erscheint
- Schritt 150: der Mondhintergrund nimmt Form an
- Schritt 300: die Details werden vervollständigt
Das Bild ist geboren.
Aber wie kann der Text das Bild steuern?
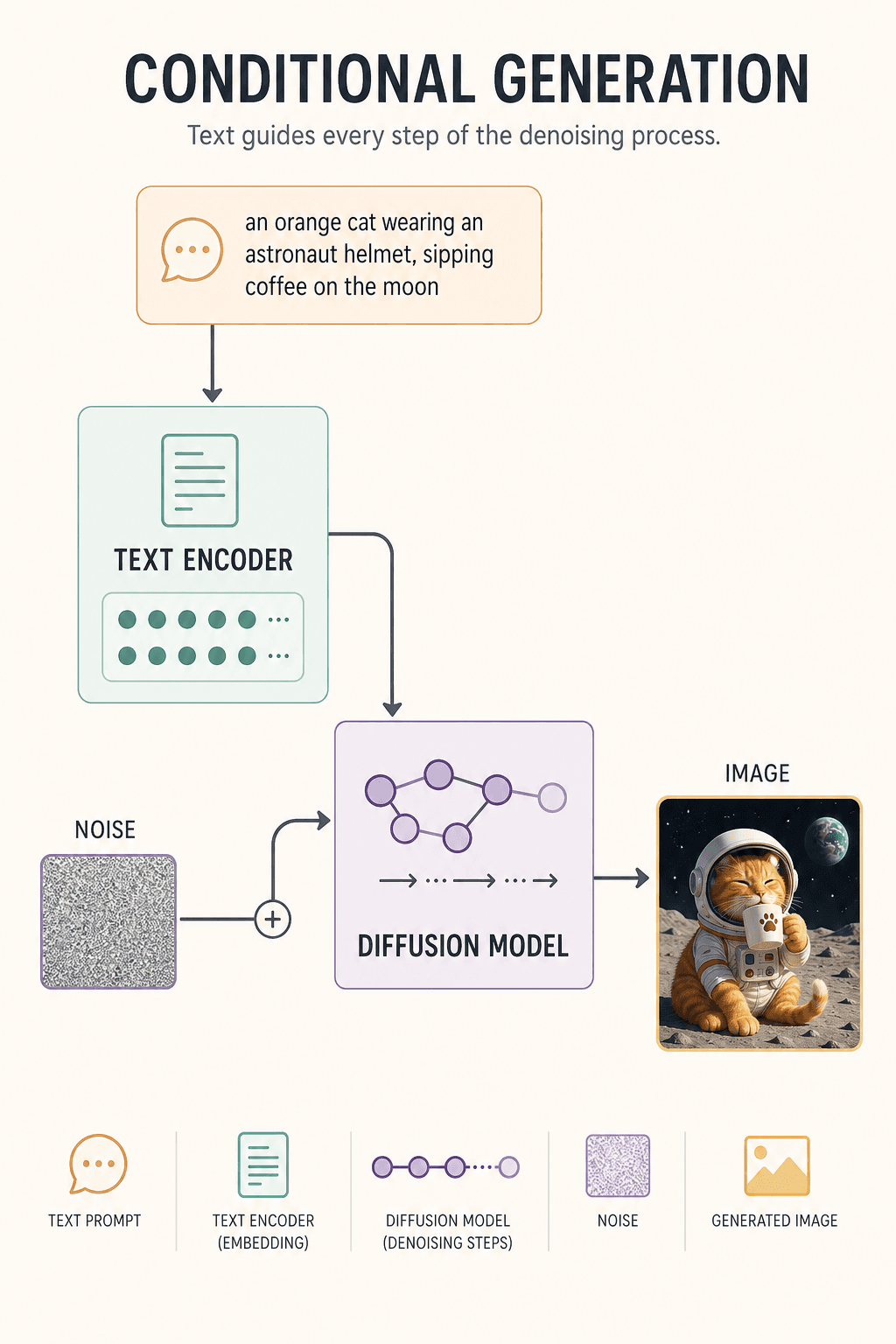
Weil es ein weiteres zentrales Modul gibt: den Text-Encoder (Text Encoder).
Er verwandelt „orangefarbene Katze + Astronaut + Mond + Kaffee" in einen mathematischen Vektor (ein Konditionierungssignal), der das Modell während des gesamten Entrauschens daran erinnert:
- „Vergiss nicht, das ist eine orangefarbene Katze, keine schwarze."
- „Wir sind auf dem Mond, nicht in einer Küche."
Das nennt man bedingte Generierung (Conditional Generation).
Warum ist Diffusion mächtiger als GANs?
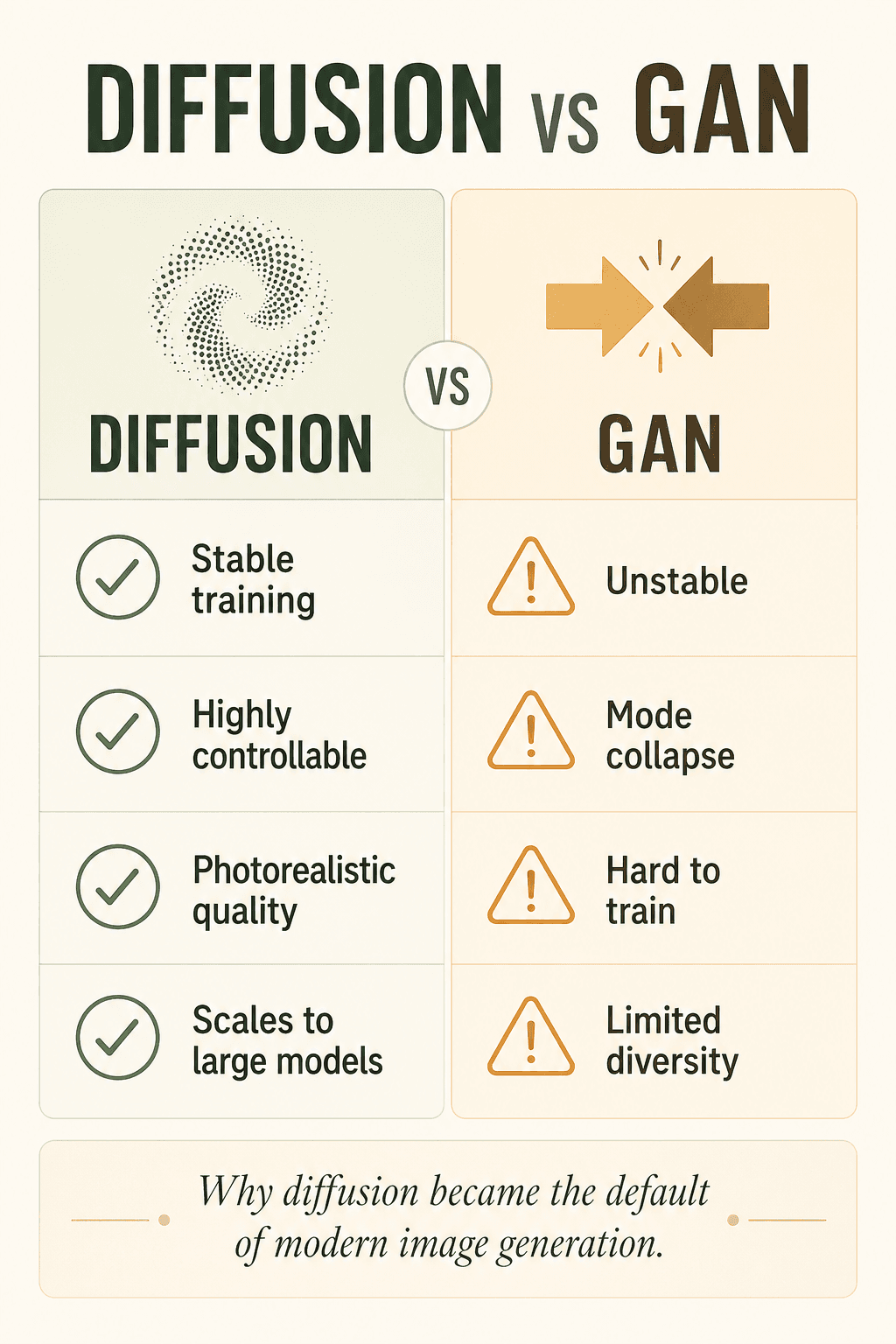
Die ersten KI-Bildgenerierungsmodelle stützten sich vor allem auf GANs (Generative Adversarial Networks). Aber GANs waren oft instabil, anfällig für Kollaps, schwer zu trainieren und wenig vielfältig.
Diffusionsmodelle sind stabiler, leichter zu kontrollieren, von höherer Qualität und viel besser an die Ära der großen Modelle angepasst. Deshalb sind sie zum De-facto-Standard geworden.
Der wesentlichste Satz
Das Wesen der KI-Bildgenerierung ist nicht „Schöpfung":
Es ist die Suche im Wahrscheinlichkeitsraum nach dem Ergebnis, das „einem Bild am ähnlichsten sieht".
Als ob man im unendlichen Chaos ständig fragte: „Was ist von hier aus der nächste kohärenteste Schritt?"
Das ist der tiefste Gedanke der modernen generativen KI.