
ブログから抜粋
霧の中の絵描き — 寓話で理解する拡散モデル
AI 配置イラスト付きで段落を抜粋。記事全文は本編で。
彼は白い紙を 1 枚手に取り — 筆を入れる代わりに、紙全体を散らかった濃い灰色の絵の具で覆った。観衆は訝しんだ:「台無しだ」。呉星は答えた:「本物の絵は、まず隠れることを学ばなければならない」。

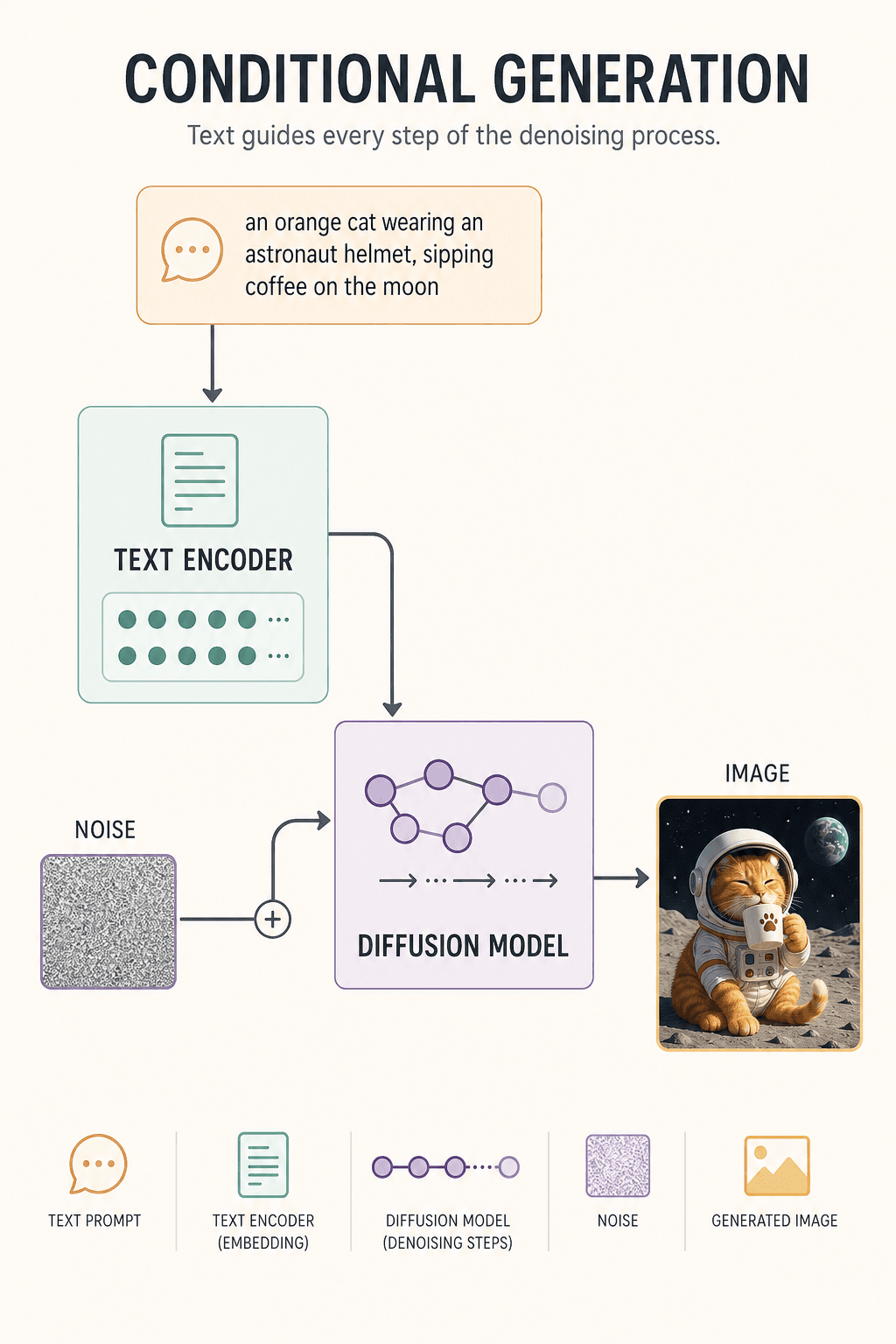
学習時、モデルはこのように学ぶ: 本物の猫の写真を取って、ノイズを繰り返し追加する — 1 ステップではまだはっきり、100 ステップでぼやけ始め、1000 ステップで純粋なランダムテレビ砂嵐に。そして AI に逆を答えさせる: 「いまこんなに乱れているなら、元はどう見えていた?」

実際の生成時、モデルには絵がない — ランダムノイズの塊とプロンプトだけ。1 ステップ: 小さなデノイズ。30 ステップ: 猫のシルエットが現れる。80 ステップ: ヘルメットが見える。150 ステップ: 月の背景が形になる。300 ステップ: ディテールが定まる。画像が誕生。

なぜテキストが画像を制御できるのか?テキストエンコーダのおかげだ。それが「オレンジ猫 + 宇宙飛行士 + 月 + コーヒー」を数値ベクトルに変換し、毎デノイズ ステップでモデルに思い出させる: 「オレンジ猫、黒猫ではない。月の上、台所ではない」。
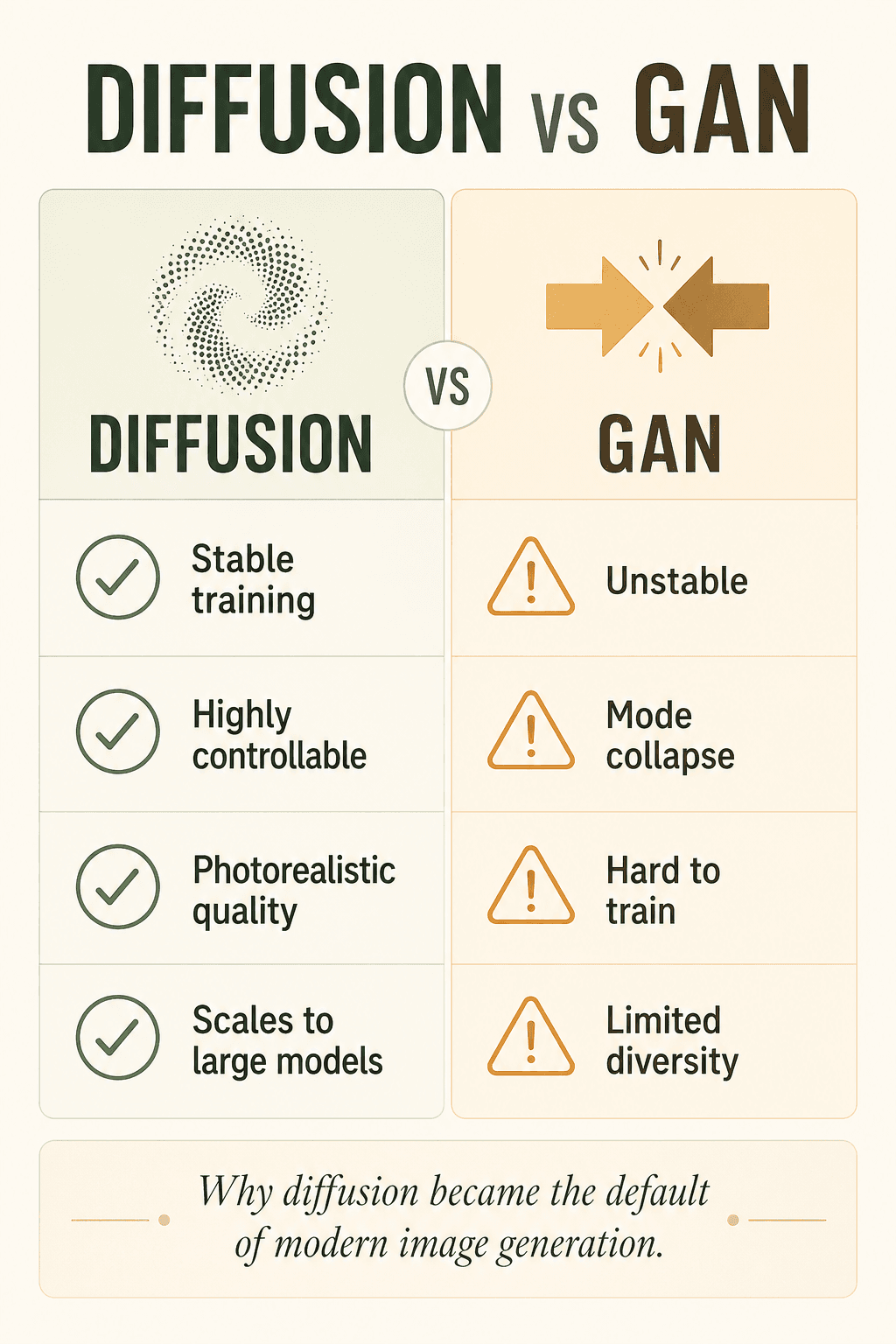
以前の AI 画像生成器は GAN に頼っていたが、GAN は不安定で悪名高く、モード崩壊に弱く、学習が難しく、多様性に欠けた。拡散モデルはより安定し、より制御可能で、より高品質、よくスケールする — だから静かに現代のデフォルトになった。
—— 約 1,500 字省略 ——