
その昔、北の山々の間に、年中深い霧に包まれた小さな街があった。白嵐城(はくらんじょう)という場所だ。街には若い絵描きが住んでいて、名を呉星(ごせい)といった。
彼には不思議な能力があった: ほかの絵描きは物事をはっきりと見てから一筆ずつ描くのに、彼はその真逆 — いつも乱れた霧の中から一枚の絵をゆっくりと「見出す」のだった。
人々はこれを馬鹿げていると思った。「霧の中にどうやって絵があるんだ?」 呉星はただ微笑むだけで、説明はしなかった。

浮かぶ図書館
ある日、城主が彼を呼び出して言った: 「存在したことのない一枚の絵がほしい — 黄昏に海の上に浮かぶ図書館、空に二つの月が出ている姿だ」。
皆が大笑いした。「世にそんな場所はない、どう描くんだ?」
しかし呉星は頷いた: 「描けます」。
彼は白い紙を 1 枚取ってきたが、すぐに筆は入れず、まず紙全体を灰黒色の絵の具で乱雑に塗った。まるで大雪後の窓のように、何も見分けられなくなった。皆はさらに混乱した: 「それは絵を台無しにしているだけだ」。
呉星は答えた: 「本物の絵は、まず隠れることを学ばなければなりません」。
その後の数日、彼は毎日たった 1 つのことしかしなかった: 乱れを少しずつ拭き取ることだ。すべてではなく、一度にでもなく、少しずつ。
今日は光と影を拭き取り、明日は海岸線を、その次の日には本棚の輪郭がうっすら現れ、さらに後には二つの月が霧の中から浮かんできた。彼はまるで深い霧と交渉しているようだった。創造ではなく、絶え間なく問いかけていた: 「ここは元々何であったべきか?」 拭き取りが間違っていれば、また判断する。ぼやけていれば観察を続ける。
合計 49 日。
最後にその紙には、本当に海の上に浮かぶ図書館が現れた。海は静かで、書架がはためき、黄昏は黄金の呼吸のようで、二つの月が遠くに掛かっていた。
霧はどこから来るのか?
街全体が衝撃を受けた。誰かが尋ねた: 「いったいどうやったんだ? 最初は何もなかったはずなのに」。
呉星は首を振った。「いえ、最初からすべてあったんです。ただ、霧の中に混ざっていただけで」。
城主が再び尋ねた: 「では、どこを拭き取ればよいかどうしてわかったんだ?」
呉星は答えた: 「先に名前を聞いたからです。『浮かぶ図書館』『二つの月』『黄昏』『海』。これらの言葉が遠くから聞こえる鐘の音のようでした。私はその音を頼りに、霧の中で道を見つけたのです」。
のちに彼は弟子を一人取った。弟子は長く学んだが、奥義をつかめなかった。彼はいつも思っていた: 「私は結果を直接描き出したい」。
呉星は彼を山頂に連れて行った。夜明け、深い霧が山を覆った。彼は言った: 「あの塔が見えるか?」 弟子は答えた: 「見えません」。 呉星は問うた: 「ならばそれは存在しないのか?」
弟子は黙った。
呉星は言った: 「絵も同じだ。お前は無から有を生む世界の創造者ではない。お前は混沌の中から徐々に最も合理的な世界へ近づいていくのだ。本物の絵は筆を置くことではない、ノイズを取り除くことだ」。
何年経っても白嵐城の人々はあの絵描きを覚えていた。彼らは言う: 彼は絵を描いたのではない。世界に、乱れの中からどのようにゆっくりと秩序が育つのかを教えたのだ、と。
物語の裏にある本当の知識: 拡散モデル
この物語全体は、現代 AI 画像生成の最も中核となる原理 — 拡散モデル(Diffusion Model) に対応しています。
Stable Diffusion、Midjourney、そして当サイトが使う GPT Image 2 — 本質的にはみなこの思想を強く活用しています。
一文で理解するなら:
最初から絵を直接描くのではなく、まずランダムノイズの塊から始めて、一段階ずつ「ノイズを取り除き」、最終的に画像にする。
物語の中の呉星のように: まず紙を乱雑に塗り(純粋なノイズ)、点ずつ拭き取り(段階的なノイズ除去)、最終的に画像を得る。
学習段階: AI に「ノイズ除去のしかた」を教える

学習時、モデルはこう学びます:
第一に、本物の写真を 1 枚用意する。例えば猫の写真。
第二に、絶え間なくノイズを加える:
- 1 回目: 猫はまだ鮮明
- 100 回目: ぼやけ始める
- 500 回目: ほとんど見えない
- 1000 回目: 完全にランダムな砂嵐
第三に、AI に答えさせるよう学習する: 「いまこんなに乱れているなら、元の絵はおおよそどんな姿だったのか?」
つまり「逆過程」を学ぶ: 乱れ → 鮮明。
これが核心です。
生成段階: 実際に絵を描き始める

実際の生成時、AI には絵が全くありません。ただランダムノイズの塊と、プロンプトが 1 行あるだけ:
宇宙飛行士のヘルメットをかぶったオレンジ色の猫が、月でコーヒーを飲んでいる姿
そこからモデルが始まります:
- 1 ステップ: 軽くノイズ除去
- 30 ステップ: 猫の輪郭が現れ始める
- 80 ステップ: 宇宙飛行士のヘルメットが登場
- 150 ステップ: 月の背景が形になる
- 300 ステップ: ディテールが完成
ついに画像が誕生します。
ではなぜテキストが画像を制御できる?
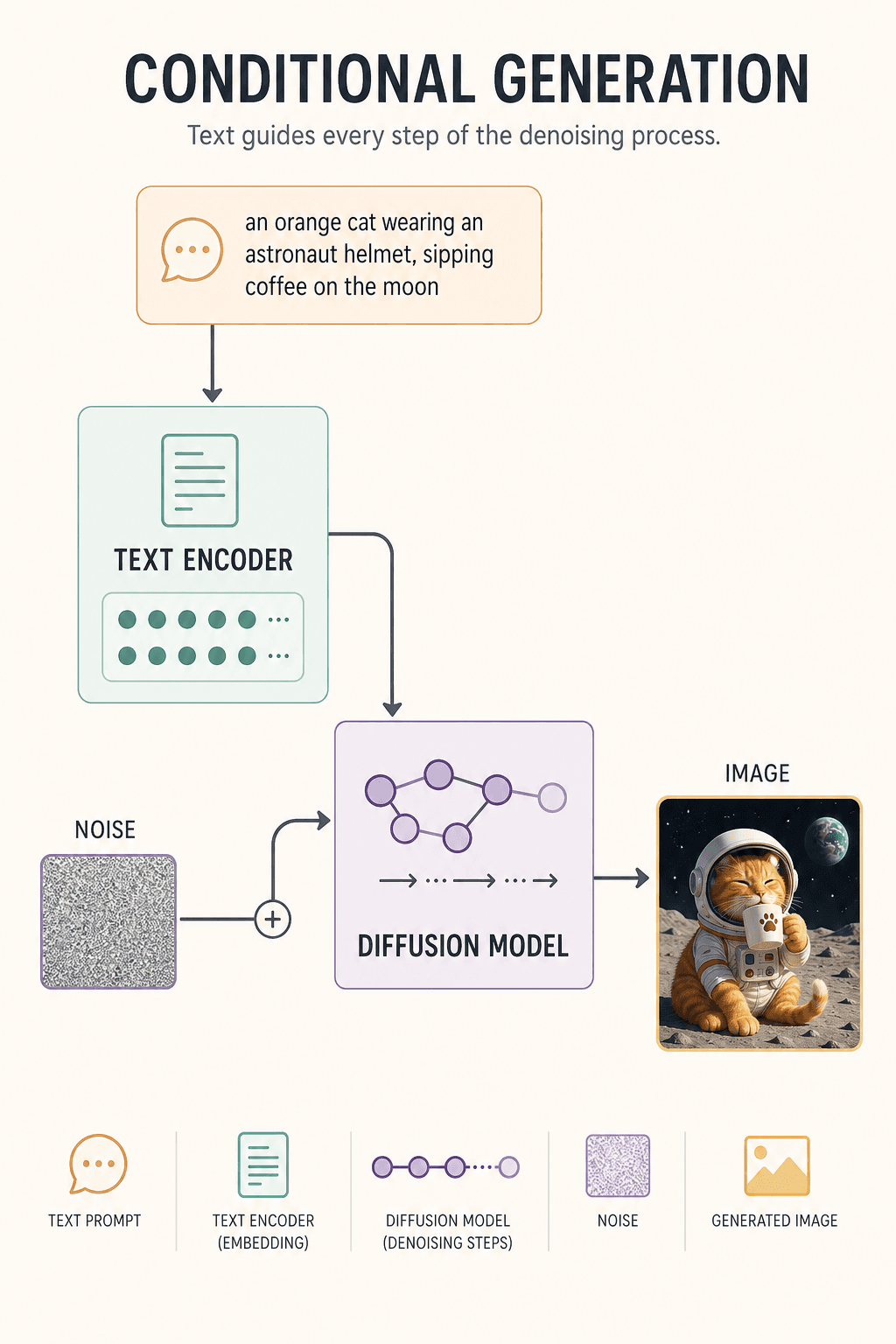
もう 1 つ重要なモジュールがあるからです: Text Encoder(テキストエンコーダ)。
それが「オレンジ猫 + 宇宙飛行士 + 月 + コーヒー」を数学的なベクトル(条件信号)に変換し、ノイズ除去の過程ずっとモデルに思い出させ続けます:
- 「忘れるな、オレンジ猫だ、黒猫ではない」
- 「月にいるんだ、台所ではない」
これを 条件付き生成(Conditional Generation) と呼びます。
なぜ拡散モデルは GAN より強い?
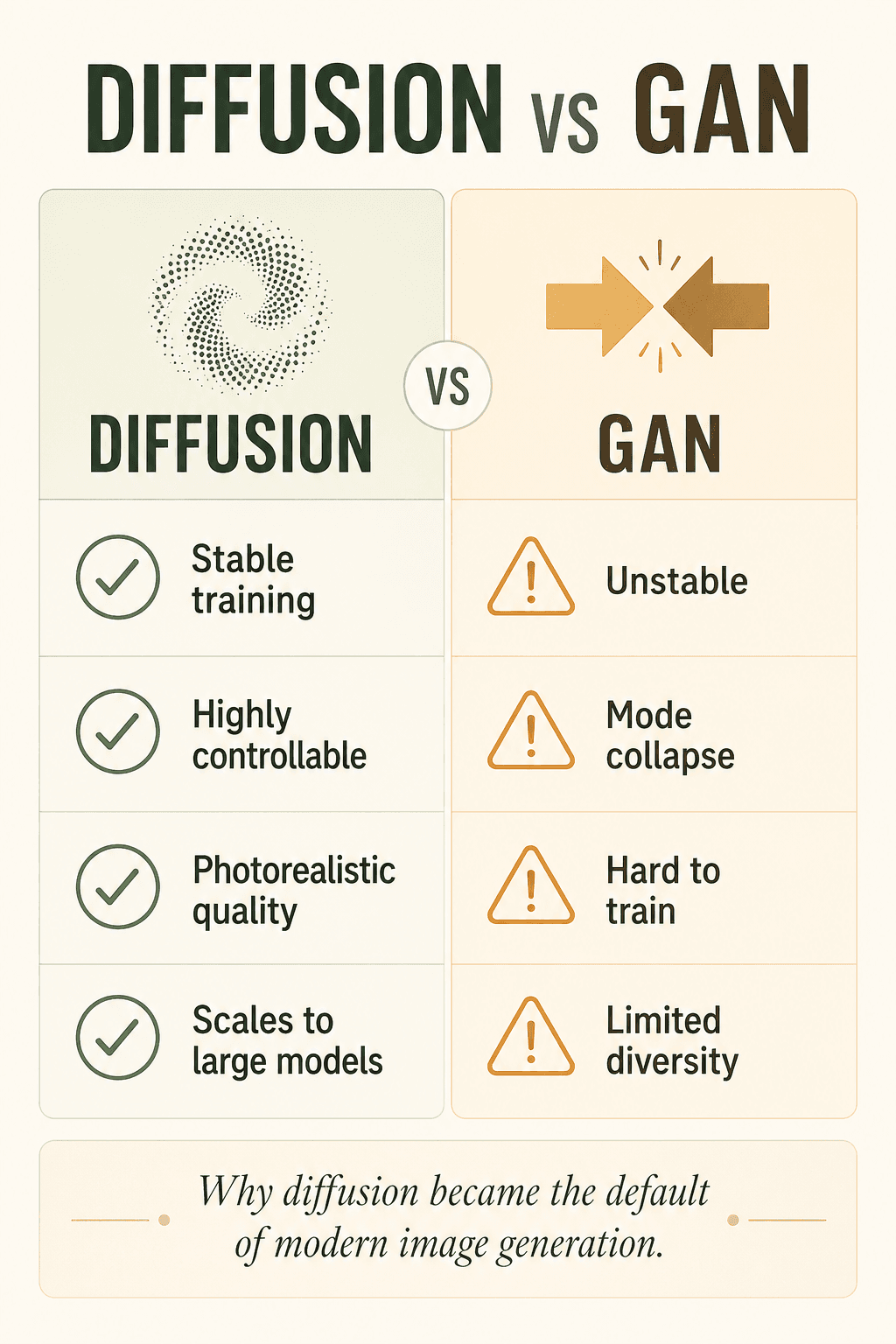
初期の多くの AI 画像生成は GAN(敵対的生成ネットワーク)に依存していました。しかし GAN はしばしば不安定で、崩壊しやすく、学習が難しく、多様性に欠けました。
一方、拡散モデルはより安定し、制御が容易で、品質が高く、大規模モデル時代により適しています。だから今や事実上の主流になりました。
いちばん本質的な一言
AI 画像生成の本質は「創造」ではなく:
確率空間の中で「最も画像らしく見える」結果を探すこと。
まるで無限の乱れの中で問い続けているようです: 「ここから最も合理的な次の一歩は何か?」
これこそ、現代の生成 AI のもっとも深い思想です。