
节选自博客
雾里的画师 —— 用一则寓言读懂扩散模型
以下为节选段落 + AI 自动配图,完整文章请阅读博客。
他拿来一张白纸,却没有立刻下笔,而是先把整张纸用灰黑色的颜料胡乱涂满。旁人困惑:「你这是在毁画。」雾生说:「真正的画,要先学会藏起来。」

训练时,模型这样学习:拿一张猫的照片,不断加噪声 —— 第 1 次还清楚,第 100 次开始模糊,第 1000 次彻底变成雪花点。然后训练 AI 反过来回答:「如果现在这么乱,原来的图大概长什么样?」

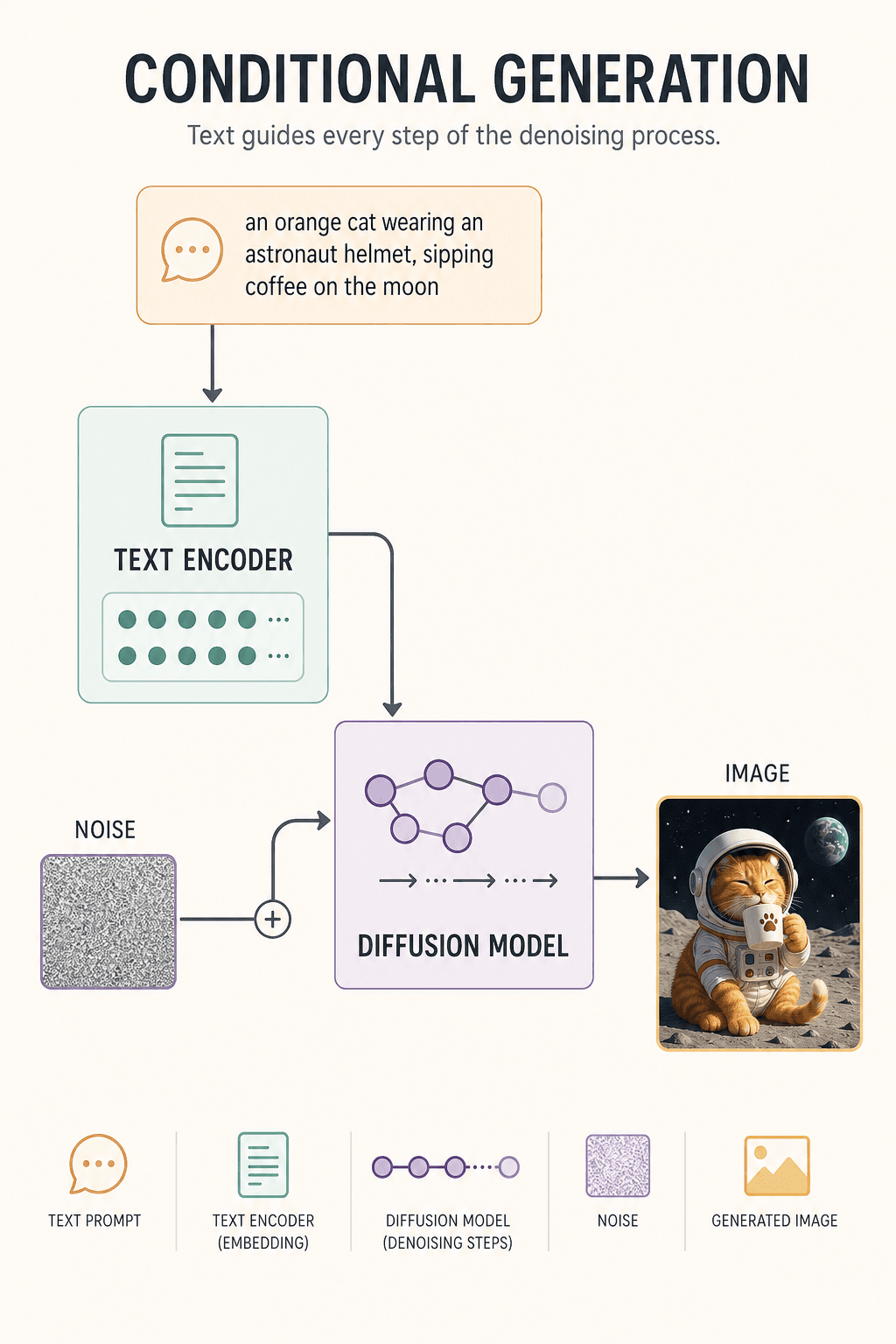
真正生成时,AI 手里只有一团随机噪声和一句提示词。第 1 步稍微去噪,第 30 步出现猫的轮廓,第 80 步宇航员头盔出现,第 150 步月球背景形成,第 300 步细节完成。最后,图片诞生。

文字为什么能控制图?因为有 Text Encoder。它把「橘猫 + 宇航员 + 月球 + 咖啡」变成一组数学向量,在去噪过程中不断提醒模型:「别忘了,是橘猫,不是黑猫。」「是在月球,不是在厨房。」
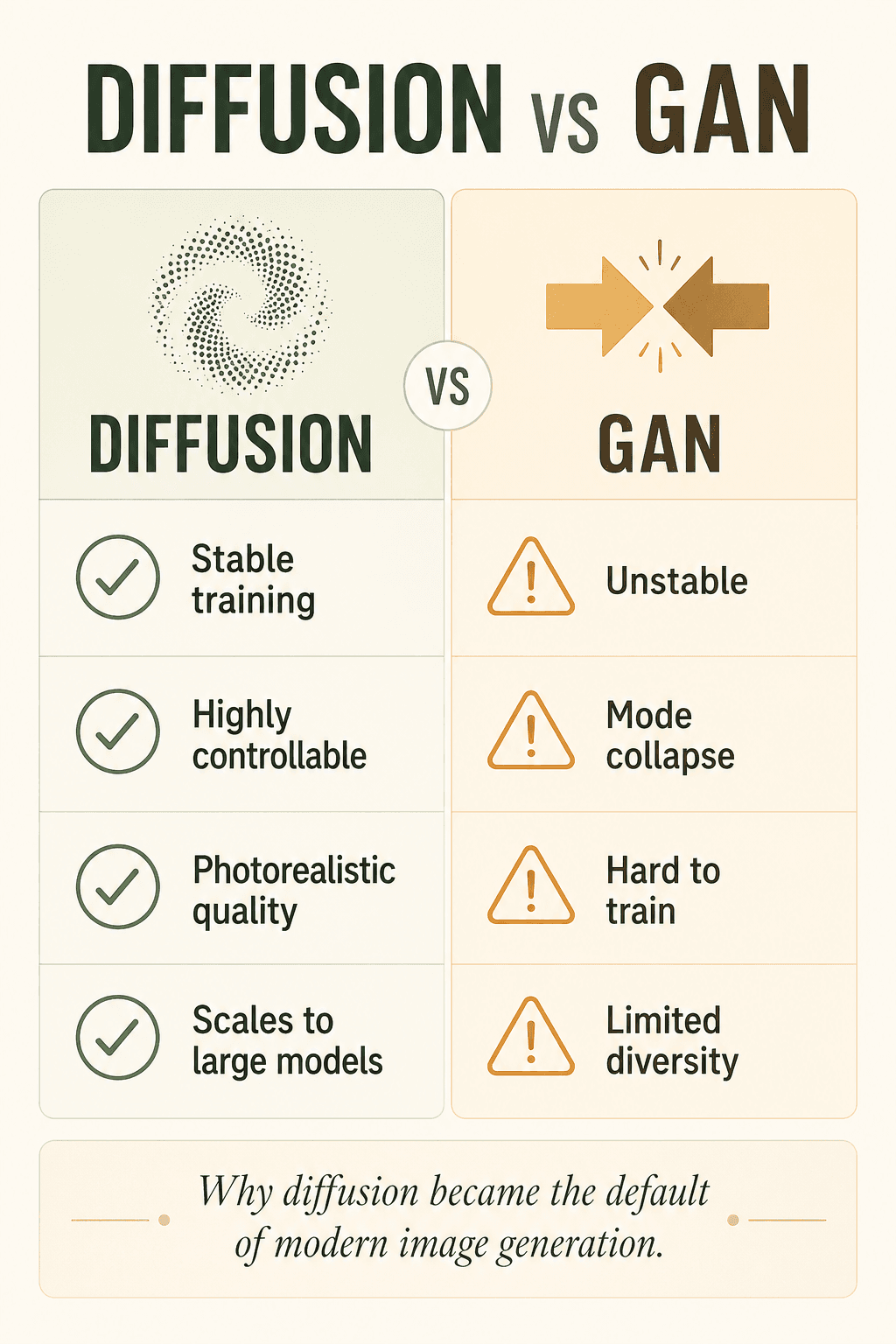
早期 AI 生图靠 GAN,但 GAN 经常不稳定、容易崩、难训练、多样性差。而 Diffusion 更稳定、更容易控制、质量更高、更适合大模型时代,所以现在基本成为主流。
—— 此处省略约 1500 字 ——